Benchmark of Python-C++ bindings
| 1565 words | 8 minutes
C++ and Python are commonly used languages with each their own benefits and costs. C++ allows writing faster programs, but has a stiff learning curve. On the other hand, pure Python is slower due to its interpreted nature, but it allows easier prototyping. In short, C++ is best for implementation of algorithms, while Python – for their configuration.
It is possible to use these languages together, using an interoperability (interop) layer, also referred to with names like “wrappers”, “bindings”. There are different areas that benefit from such arrangement – applications with addons (e.g., Blender), game engines (e.g., godot-python), tools for scientific computations (e.g., scipy).
To achieve this interoperability, there are a lot of tools and options – there’s a review that covers most of them. This post attempts to provide an example of how these tools can be used, as well as measure the resulting overhead of the generated interop code. Such overhead consists of a function call and wrapping/unwrapping data types for function arguments and return values [1].
Benchmark structure
Source code: https://github.com/yanto77/cpp-python-binding-benchmark.
The benchmark implements two test scenarios – generation of Mandelbrot set image and simulation of Conway’s Game Of Life. Both scenarios consist of Python scripts with different complexity (single, simple, complex), a set of interop modules (only one is used at a time), and the C++ implementation which the interop module utilizes.

Testing scripts
Below is the inner loop of Mandelbrot’s complex test script. The simple test script is different only in that it combines scale(), get_iterations() and get_rgb_smooth() methods into a single call. Similarly, single test script contains only single get_image() call, without any loops.
| |
While this is maybe a simple example, it can be argued that these scripts represent other real-life use-cases sufficiently enough. This is because for the purposes of this benchmark, the number of function calls crossing the C++/Python boundary seems to matter more than what those function calls do exactly. An example with a game scripting context could look as follows:
| |
Similarly to simple test case, to reduce function calls, the distance_between(get_node(idx), player) consisting of two calls can be replaced with single distance_to_player(node_idx). Alternatively, the whole loop can be replaced with process_nodes() call that does everything within C++ scope without crossing C++/Python boundary.
So, the difference in the Python scripts is in the total number of calls they make into C++ library. With Mandelbrot scenario, the number of calls depends on the image size (X1, Y1). The benchmark uses default values (X1 = 1000, Y1 = 1000). With Game of Life scenario, the number of calls depends on board size (X2, Y2) and the number of iterations (Z2). The default values are (X2 = 200, Y2 = 200, Z2 = 100). The table below present the resulting totals.
| Test case | Function calls | Total number |
|---|---|---|
| mandelbrot-single | 1 | 1 |
| mandelbrot-simple | 2 * X1 * Y1 | 2,000,000 |
| mandelbrot-complex | 4 * X1 * Y1 | 4,000,000 |
| gameoflife-single | Z2 | 100 |
| gameoflife-simple | Z2 + 3 * X2 * Y2 * Z2 | 12,000,100 |
| gameoflife-complex | Z2 + 10 * X2 * Y2 * Z2 | 40,000,100 |
Interoperability modules
The table below lists interoperability modules that are currently included in the benchmark. They are categorized on manual-automatic and static-runtime axes.
| Manual | Automatic | |||
|---|---|---|---|---|
| Static | manual bindings, Cython (0.29.32) | pybind11 (2.11.0.dev1), nanobind (0.0.5), SWIG (4.0.2) | ||
| Runtime | CFFI (1.15.1) | cppyy (2.4.0) |
Manual-automatic refers to how much the tool can generate. For example, SWIG just needs to be pointed to a header file and it will parse and generate a shadow class automatically, while Cython requires you to specify both the definitions (*.pxd) and the wrappers (*.pyx) manually.
Static-runtime axis shows if the bindings are generated during script’s runtime or beforehand. The output of the static tools consists of two shared objects – the one containing the library code and the one with the binding code. For the runtime tools, there’s no library with the bindings, as they are generated on request. For this, distribution requires library’s public headers and the machinery required to parse them (the cffi or cppyy modules). To be specific, cffi doesn’t actually need a separate header, as you inline the relevant parts in the cdef(), but to parse that you still need the cffi module.
For SWIG, it was possible to configure it to generate different kinds of wrappers using build options -builtin and -fastproxy. For this benchmark, both options improved the runtimes, but -builtin was the better of the two.
Results
The results below show how long it takes to run the main part of the testing scripts, for different scenarios and different interop modules. The cpp entry is the baseline that implements the functionality with only C++. The cpy_* and pypy_* entries are the test scripts executed with CPython (3.10.4) and PyPy (7.3.9), respectively. Clicking on the images will open them in full-scale.
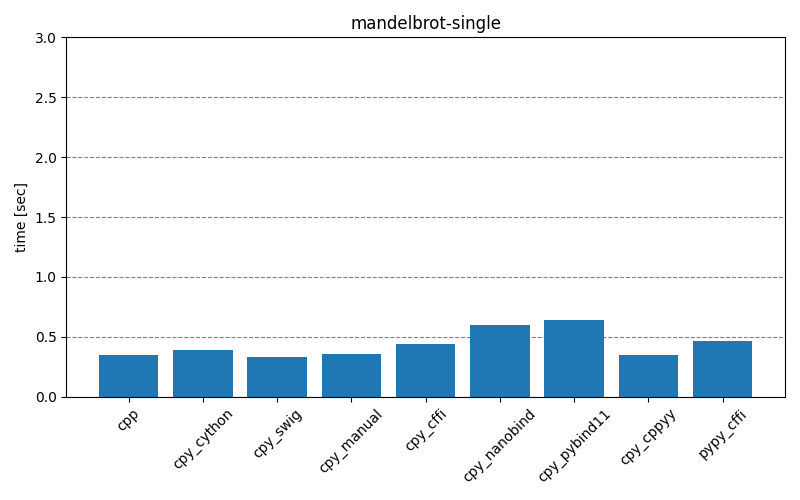
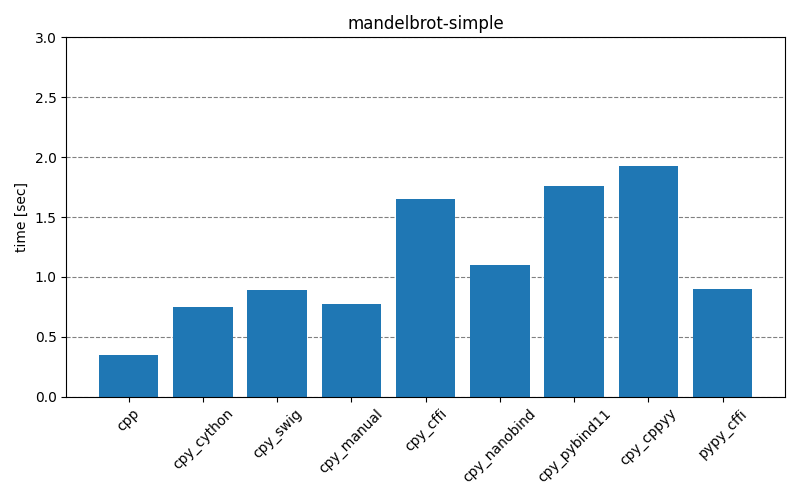
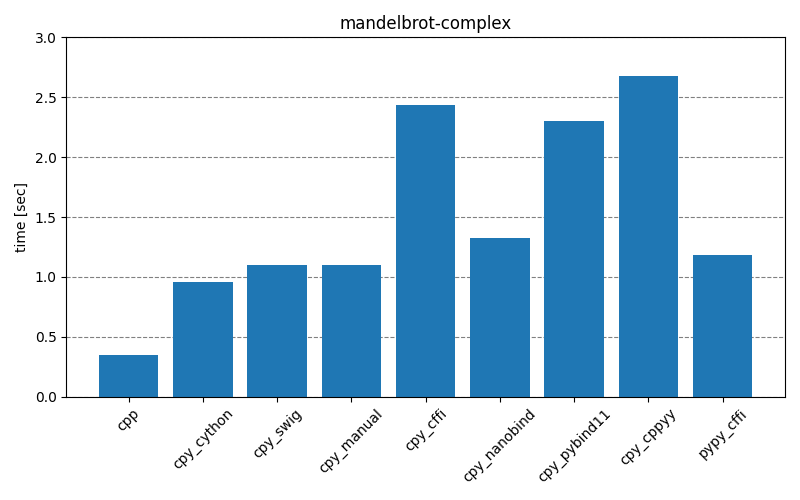
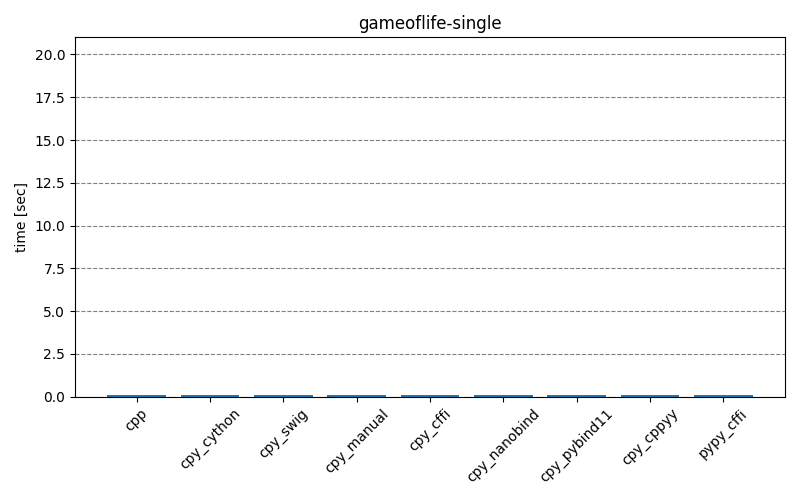
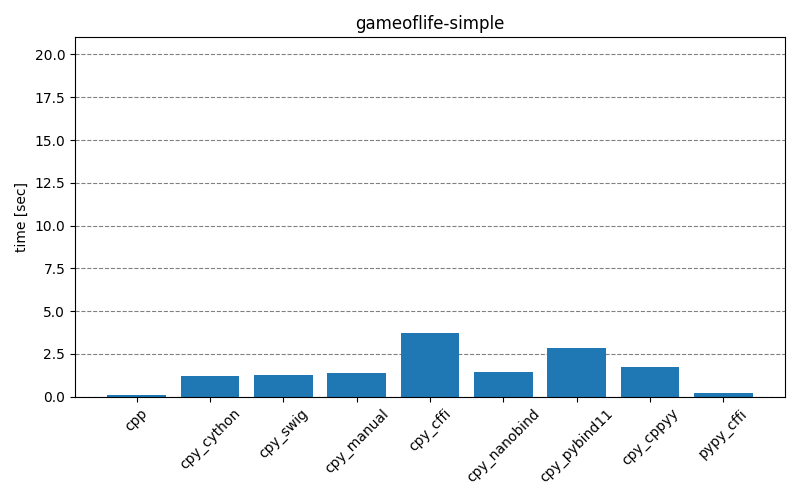
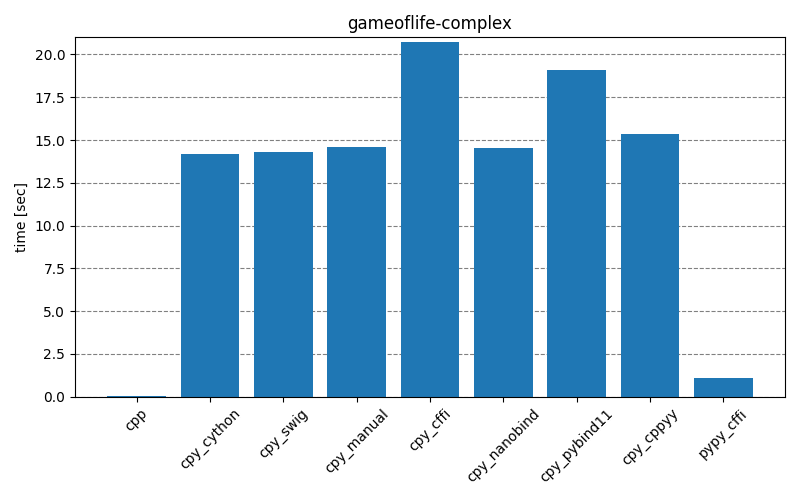
Overall, it’s clear that for best performance the least amount of interoperability should be preferred – either implementing the functionality fully on the C++ side or providing Python API consisting of single function call to complete the necessary operations without extra overhead. With such approach, the choice of interop module doesn’t seem to matter too much. For real-life projects, it could be that there will be a large number of different function call permutations. This makes it unfeasible to create individual APIs for every situation, setting aside the point that some permutations maybe be unknown a priori when there’s an external consumer.
Comparing results of interop modules, there seem to be two groups with behaviors quite close to each other. First group, consisting of cpy_cython, cpy_swig, cpy_manual, cpy_nanobind, contains a lot of static modules, and second group, consisting of cpy_cffi, cpy_pybind11, cpy_cppyy, is more about the runtime bindings. While cpy_pybind11 doesn’t generate bindings during runtime, there still seems to be a lot of overhead, compared to the first group.
A clear outlier is the pypy_cffi module – with Mandelbrot scenario it behaves similarly to the first group, but with GameOfLife scenario it’s closer to the C++ implementation! This is especially obvious in the gameoflife-complex, but the effect is there also in gameoflife-simple – the exact run-times are presented in the table below. It’s unclear to me why there is such a big difference. The python test-scripts differ in that gameoflife-* has three for-loops inside one another, while mandelbrot-* has only two, but I’m not sure that is relevant at all.
| cpy_nanobind | pypy_cffi | |
|---|---|---|
| mandelbrot-simple | 1.10 sec | 0.9 sec (-18%) |
| mandelbrot-complex | 1.34 sec | 1.17 sec (-13%) |
| gameoflife-simple | 1.43 sec | 0.21 sec (-85%) |
| gameoflife-complex | 14.06 sec | 1.05 sec (-92%) |
Conclusions
This started as a study of how to do Python bindings for C++ codebase. It became more clear to me that the question of providing bindings does not have a single definitive answer, but instead a range of options, each with their benefits, issues, and history. The benchmark is a personal attempt of making sense of these different projects.
In addition to numbers, there’s usability aspect to these projects – how easy it was to get up to speed with them. This is purely subjective, so I’m separating this part here:
- With CFFI, I have the issue that it’s unclear if everything has been wired up correctly. Other projects often provide compilation errors on unresolved symbols or mismatched types, leading to increased sense of safety when the project built successfully. To guarantee safety for CFFI bindings, I guess one would need to test the binding code manually or create unit tests for the exposed API. As the wrapped C++ project is probably tested already by itself, such unit tests would mostly create copies of existing tests.
- The CPython API (manual bindings) is one of the most verbose APIs. There’s a steep learning curve and it’s easy to make hard mistakes. For example, I learned the hard way that
Py_Trueis a ref-counted object and it shouldn’t be returned from a function without incrementing the ref-count. If not done properly, the program may segfault in very different location (when the ref-count reaches zero) and it may be relatively hard to establish the correct cause-and-effect link. No other project made me think about returning a single boolean this much. - I think the most effective I was with
pybind11andnanobind, as their API is a pleasure to work with and it’s easy to learn. That’s why I was slightly sad that benchmark showedpybind11to be one of the slowest modules. However,nanobindimproves the performance a lot, while preserving the same API. It seems that some features didn’t make it, but within this benchmark project it was not noticeable.
In addition to being my first step into this world, the benchmark is based on example scenarios. That is, it doesn’t use any real-life project, but attempts to model the behavior using simplified examples. As such, it is debatable if the quality of such models allows generalizing the results to real-life projects. Overall, the benchmark is not definitive, but hopefully provides enough context and data points for a larger evaluation.
References
Other similar comparisons:
- https://github.com/tleonhardt/Python_Interface_Cpp
- https://github.com/wjakob/nanobind (see benchmark details here)
- https://github.com/ros2/rclpy/issues/665 (see linked design document)
Other useful references: