Advent of Code 2020
| 2019 words | 10 minutes
Advent of Code has caught my attention a couple years before, but I did not pick it up at that point. The 2020 event was the first one I attended and, after completing it, I’m happy with the time spent on it. I did not approach it as a competition: my initial commit dates 8 Dec 2020 and the 50* commit – 6 Mar 2021. Some of these days I didn’t touch the project at all. In the end, I was able to write solutions in C++ to all puzzles, adding up to 2 seconds of execution time on my hardware.
| |
Initially, I expected to find the solutions to the puzzles relatively easily. Projects such as Voltara/advent2018-fast set my mind on optimizing the solutions more than solving them. Quickly, I found out that the learning curve is not as easy as expected. For the solutions to run less than 15 sec, one is expected to use many data structures and algorithms.
Overall, I’ve enjoyed the process of creating the solutions to the puzzles. There were puzzles I was stuck on and couldn’t do without reading and studying the solutions of others (e.g., Day 13, Day 19). Comparing the execution times against Voltara/advent2020-fast, compiled and executed on the same hardware, yields following results:
- 17 of my solutions are 1-5 times slower,
- 5 solutions are 20-80 times slower,
- and 3 solutions are slower by 230, 9500, 14000 times.
I am happy with my results, but there’s definitely possibilities to improve the solutions even more. Below, I would like highlight couple of days that surprised me the most.
Day 5
One of the exciting parts of completing a puzzle is to compare own solutions against others. There are opportunities to learn from other people in how approached the problem, ranging from the general method to how they write the solution down. The solutions are often composed from inter-changeable parts, allowing experimentation.
One of such experiments is presented below. Part of the solution was to parse seat numbers like FBFBBFFRLR. I, as many others, chose to convert this to an integer – like 0101100101. Below are two common variations of this function: convert_line1 combines the loops and if-clauses into one, while convert_line2 keeps them separate. The surprising thing here is the effect on the runtime. With convert_line1 the whole solution executes in 77-78 μs, while with convert_line2 – in only 14-16 μs (-80%).
| |
In a sense, the difference is understandable, because in convert_line1 some conditions are evaluated which are definitely false: line[i] == 'R' for the first 7 chars and line[i] == 'B' for the last 3 chars. Assuming uniform distribution of input values, there will be 3.5 + 3 unnecessary comparisons done for every input. Thus, switching to convert_line2 reduces the number of comparisons by 40% (from 16.5 to 10). But, this reduction doesn’t in itself explain the runtime difference.
Statistics recorded with perf stat -r 1000 show surprisingly consistent number of branches. The difference in the number of branches between convert_line1 and convert_line2 is ~9000. Dividing it by 6.5 gives 1384 lines, yet there are only 908 lines in my input. Instead of guessing, we can also calculate the number – there are 3213 F’s, so number of skippable if-clauses is 5937 (3213 + 908*3), which is not that close to 9000 either. Not sure this all makes sense, but reducing if-clauses clearly has greater effect than single operation cost.
Day 23
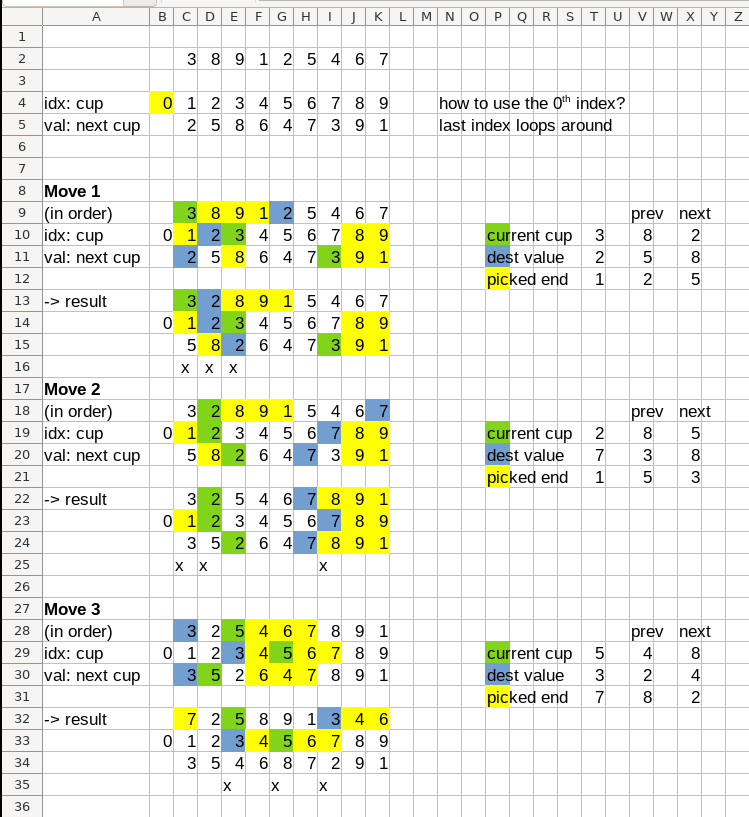
The contrast between the solutions for both parts for Day 23 was probably the most memorable for me. The puzzle gives a list of 10 numbers and asks to re-arrange them based on specific rules. Well, I saw small input and I saw parts moving around, so the solution I came up with for the part 1 is to copy things around. With this approach, each part must be copied in correct order: first the current cup, then all cups up to the destination cup, then the destination cup itself, then 3 pickup cups, and finally the cups after the destination cup. As you might imagine, doing this with 10 numbers for 100 loops is very fast. One might even think that this would an optimal solution!
The part 2 grows the input size to 1,000,000 and asks to loop around 10,000,000 times. The approach of copying things around between two buffers blows up to infinite runtime, assumingly, as I didn’t care to wait. The important part to understand here was that instead of considering the cups, one must consider the links between them! I stepped through the moves in a spreadsheet and found that only three links are relevant in each loop. Considering only them reduces the number of copies from 1,000,000 to 3! The effect of this is that the runtime of the solution stays around comfortable 300 ms.
Focusing on the value swapping, I used a buffer to save the values and write them back in required order (see swap1 below). Later, I found out about std::exchange and std::swap, so I experimented with variations swap2 and swap3. In the end, the effects between them are seem to be quite small and the output assembly is similar (see https://godbolt.org/z/sxo97h). Using std::swap results in two extra movs, as it does one extra read and write that we know is unnecessary. swap1 and swap3 produce similar output with exception of register usage: the std::exchange version re-uses eax register and must read/write it twice, while swap1 uses three separate registers.
| |
Optimizations
The background I have for the optimization is the course I attended in the university – Programming Parallel Computers. The course is about creating a simple program and optimizing it in different stages to see the runtime drop from 99 seconds to 0.7 seconds. As the course page describes, “achieving good performance on a modern CPU is much more than simply using multiple threads”.
To collect benchmark statistics, I’ve used perf, but there are also other tools. Using perf record to see the parts that take most time is a great first step. From the numbers I’ve seen usually, the trace frequency has been ~60 kHz for me, yielding resolution of the events ~16 μs. perf stat outputs a set of statistics, some of which are above my level of understanding, but great answers on SO help with that.
Overall, I’ve learned multiple things when attempting to optimize the solutions.
Using multiple threads (e.g. with openmp) is often unnecessary, as the solutions are often in the microsecond range. If the solution for any given day takes too long to execute, there are other things to look for and threads are rarely the answer. From some simple measurements, it seems that multi-threading is more relevant in the millisecond range.
Profiling with resolution of 16 μs may yield too crude results. For some solutions such resolution yields less than 5 events per execution. And some of these solutions can be even faster, by a factor of 2-5, at least comparing to advent2020-fast. As such,
perfseems to be relevant only up to a certain point.Limiting integers to specific sizes was less of a thing than I expected. That is, using
intversusint8_t/int16_t/etc. During Day 4, the data struct in my solution could be packed from 56 bytes to 40 bytes (-28%), which sounds great on paper. Yet, the amount of data in these puzzles is so small, it lowers the memory usage by only 4640 bytes, without much effect on runtime. So, the memory size is not an issue within the scope of these puzzles.In general, the compiler does so many things that without measurements it is not trivial to say how/if a change is going to affect the performance. For example, in solution to Day 11 Part 1, I’ve extracted the inner loop calculating occupied seats into its own method. For some reason, simply moving the code into different place alone reduced the runtime from 7700 μs to 5900 μs (-23%).
Reflections
Finally, I would like to reflect on this experience from point of view of learning. I feel it is important that the puzzles do not limit the user in any way, allowing to use many different data structures and algorithms. This makes the bruteforce solutions (often) as valid and applicable as math-y solutions. In addition, Eric Wastl mentioned during FOSDEM talk (around 20:25) that the two-part structure of the puzzles intentionally attempts to simulate real world environments with code maintenance and end-user wanting new things out of the same code.
Consequently, one of the major areas I’ve personally felt noticeable improvement was in using C++ language itself. Specifically:
During initial days I was slightly lost with parsing the data. I’ve used a regex library for that (e.g. Day 2). Later I created and started using a set of common parsing helpers and state machines for more complex input formats (such as Days 4, 7, 14, 16).
Also, it was easy to experiment with some C++ features that were new for me, such as
<string_view>,<bitset>,constexprandstatic_asserts. For a while I’ve read from different sources thatstd::string_viewshould be preferred overstd::stringin certain situations. But, I didn’t had the chance to actually try it on something non-trivial. AOC puzzles here take the sweet spot between reference examples, which tell “how” but skip on “why” and “where”, and pre-existing codebases, where it may not be wise to add a new feature caveats of which are not well understood.Lastly, as the programming is often a community effort, it is a great exercise to read and understand the solutions of others, e.g. from the reddit community. When doing that, I’ve found out that sometimes I write very verbose solutions. It was very surprising to find how well other people were able to express similar concepts in their solutions with much more clarity and less cruft.